Previous Entry: Data Tension Examples Next Entry: NumPyro Workshop
Go Back: Statistics Articles Return to Blog Home
The jupyter notebook for this article, including all plotting code, is available here.
Is the Raffle Rigged? Practical Stats for a Toy Problem
Over the Christmas break, I was presented with an interesting question. A family member, frequenting a local sports club raffle, had become suspicious that the ticket numbers were being drawn in unusual “lumps” instead a truly “random” uniform pattern. As the ranking statistician in the family, I was pitted against the problem of answering a simple question:
Is something funny going on?
You’ve almost definitely run across something similar in your own life: an ostensibly random process that, by coincidence or conspiracy, seems determined to have a personal vendetta against you. The human mind is pattern-seeking, and famously terrible at reckoning with true randomness. Our brains expect smoothness, and raise false alarms whenever this expectation is upset, with superstition and suspicion to follow soon after. This is where statistics makes itself useful. The statistician has two jobs: firstly to tease out true patterns in systems too large for an individual human to comprehend, and secondly to properly recognise the threat of coincidence in systems so small that the human mind over-comprehends them. The trained statistician’s lot is to answer life’s most difficult questions with the most confident “maybe”s of all time. This is an unimpressive trick and rarely gets you invited to parties, but it’s important all the same.
In this article, I vastly over-complicate an investigation this raffle fairness. Unlike the other articles on this blog, this is aimed at a reader untrained in advanced statistics. Over the next four sections, I’ll step through ways of attacking the problem in increasing levels of complexity, starting from “common-sense” approaches that you could imagine yourself creating (e.g. bootstrapping) and steadily advancing to the high-level tools you’d see applied in astrophysics (e.g. the Kolmogorov–Smirnov Test). At each step, you’ll see how the organizing principle for is the framing of our original question in a new and specific way, and how this question evolves over time as we ask more specific things about the world.
The Setup
Tickets begin selling each night at some lower limit, and are purchased contiguously until the raffle begins. Tickets are cheap and players can buy as many as they like, so the number sold can easily enter the thousands. When the raffle arrives, ticket numbers are drawn randomly between the lowest and highest numbers sold, ignoring and duplicates, continuing until every prize has been awarded (typically a dozen and a half or so). If all goes well, these ticket draws should be completely random and completely uniform: any two numbers should be equally likely to come up.
The Data
The data we have to play with a real-world draw numbers for $188$ nights, totalling $2,976$ tickets, as well as the upper and lower bounds of the tickets sold that night. The number of sold tickets on any given night ranges from a few dozen to 10s of thousands, while the number of draws ranges from a handful to a few dozen.
The Concern
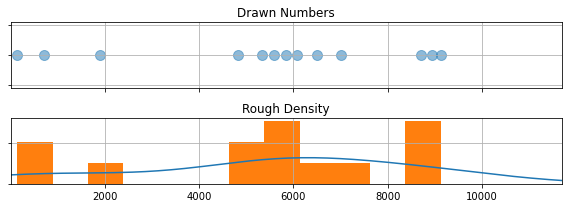
Consider the following: a night where $13$ numbers are drawn between $11$ and $11,680$. Instead of a nice uniformity, the numbers seem to be weirdly clustered around $\approx 6,000$, with the remainders falling into two other tight clumps (See the graph below). This seems unusual, but how unusual? Would you have to play a hundred games to get that kind of clustering? A thousand? This is the first step we take in our analysis, properly defining our question:
How close are the ticket draws to a uniform distribution?
Part One: Rules of Thumb and Common Sense Diagnostics
In this section, I’m going to forego any hard statistical tools and attack this with the sort of common-sense approach that someone untrained in statistics might use. These approaches might be simple, but they still have real use even in complex problems: they act as a sort of “quick glance” you might use to satisfy your curiosity or direct your focus. Specifically, I’m going to call on two new tricks:
- Sorting the tickets in order
- “Bootstrapping”
Sorting
The first thing we need to do is organize our data in a way we can make sense of. The “number line” approach I used above is cluttered and hard to read, and the histogram below is coarse and patchy. We have too few tickets to build up a clear picture of the way the tickets are distributed, so trying to “bin” them gives a choppy graph where the smoothed curve we overlaid on top doing a lot of guesswork.
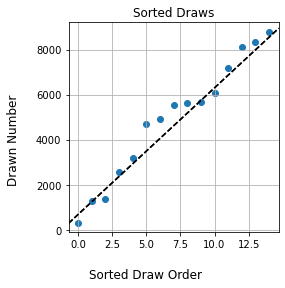
A natural next step is to instead sort the draws in order from smallest to largest, and then scatter-plot them. This un-clutters the number line, but also avoids “binning” the tickets into number ranges. There’s another advantage: if the tickets were perfectly uniform, they would sort into a clean, straight line. We’ve got a concrete way to ask our question now:
How much do the sorted draws differ from a straight line?
If the draws show a large deviation from a straight line, this suggests that something is going funny with the numbers.
Boostrapping
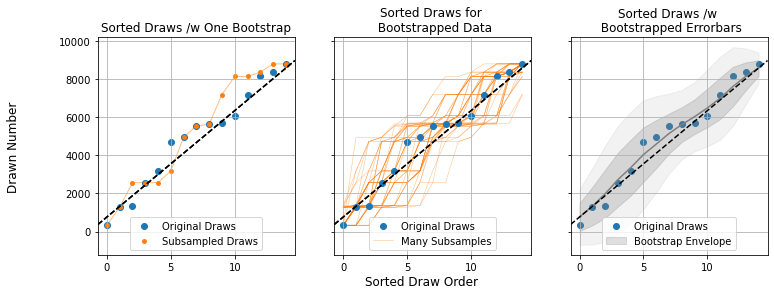
I skipped an important detail here. I used the phrase “large deviation”, but what exactly constitutes “large”? Yes, the sorted draws have some wobble, but is it a lot of wobble? To answer this, we can invoke the nifty trick of bootstrapping, a technique that asks “using only what we know from our measurements, what sort of similar results could I have gotten”? In our case, the trick goes like this:
- Take the total data set (the list of $15$ raffle draws)
- Randomly subsample these, re-selecting another $15$ randomly from this list, allowing for double ups
- Repeat the sorting and plotting we did for the original draws (Left panel)
- Repeat steps 1-3 many times (Middle Panel), noting how wide a spread you get in the results (Right Panel)
Doing this a few hundred times (middle panel), we build up an envelope of how the sorted curve might look if we “smudge” it to account account for coincidence (right panel). This tamps down the effect of outliers and makes things fuzzy enough that only large, significant features really stand out. For our example night of raffle draws, we can see that the wobbles fall well within the bounds of random chance.
Bootstrapping, applied properly, is a nearly universal tool for getting a rough idea of how important the bumps and variations in a data set are. If they disappear entirely into the smudgy bulk of the bootstrap, they’re likely just a result of coincidence. Bootstrapping comes with a weakness though: we draw our fake data from permutations of the real data, a dangerously circular process. Bootstrapping is like a Swiss-Army knife: a great and versatile tool for a first pass, but rarely the best tool for a given problem.
Part 2: Normalizing
Bootstrapping lets us get a rough feel for how unusual our results are, but doesn’t take us far down the path of understanding. Ratcheting the complexity up a tiny notch, a good next step is to normalize our ticket draws. We know that each ticket is drawn between some high and low boundary, so we can replace the actual numbers with a measure of where the draws fall within that range:
\[r = \frac{draw- lower}{upper-lower}\]This is basically squashing / stretching the draws from every night into a bracket from $0.0$ to $1.0$, allowing us to properly compare them to one another. The trick of normalizing opens up two possibilities:
- We can compare how “clumpy” the draws from each night are on the same graph (Left)
- We can lump together all of the nights into a big pool to get a feel for how lumpy the results are overall (Right)
From here on out, I’ve swapped the “sorted list” of draws for the cumulative distribution function (CDF), for all intents and purposes the same thing just rotated 90 degrees. The CDF measures what fraction of tickets are drawn below a particular number, i.e. if $CDF(x)=0.5$, that means $50%$ of tickets are $x$ or lower. For a properly uniform distribution, the CDF should be a straight line: half the tickets should fall below $r=0.5$, a quarter below $r=0.25$ and so forth.
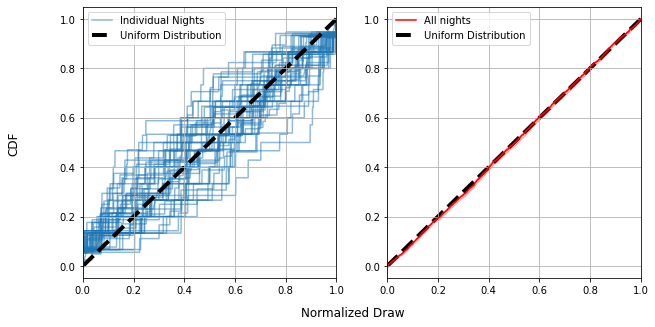
Each individual night (blue lines, left) can look pretty far from uniform, with their CDF’s spidering out all over the place. This doesn’t tell us much more than our bootstrapping approach before: some nights are pretty uniform, others less so, but it does tell us that the ensemble of all nights is not biased: The entire set of lines is centered on the straight line of the uniform distribution.
We can also see that, with every draw from every night put together, things are very close to uniform (Right). This tells us that the draws are (in aggregate over all 188 nights) pretty close to uniformly distributed.
Part 3 - P Values & The KS Statistic
So far we’ve seen ways to properly visualize the draws for a given night, along with the “fudge factor” we have to allow for by virtue of coincidence, as well as ways we can combine the data from all nights to get a feel for large-scale patterns. This sort of visual inspection is valuable for identifying anything weird, but there’s an important next question in actually interpreting this weirdness:
What are the odds of an outcome this strange occurring?
With this question, we breach the threshold of actual numbers. To answer it, we need to make the leap to some denser statistics. Specifically, we need to introduce two new things: a test statistic and the P value.
In basic terms, a test statistic is just some numerical way of quantifying “weirdness”. Here, I’m going to use a natural choice: the largest distance the CDF gets from the straight line of a uniform distribution. This has a name: the Kolmogorov-Smirnov statistic, or “KS Statistic” for short.
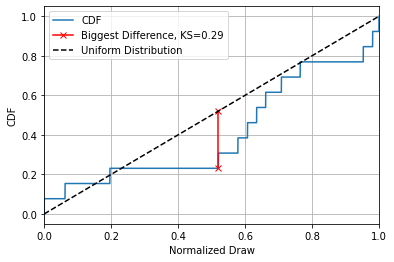
This is far from the only choice we could’ve made, even for answering our pretty tightly defined question of “how uniform are the draws”? We could have used the average distance between the lines, the total “square difference”, some kind of measure involving the bootstrapping interval, or any number of other things. As it happens, the exact choice isn’t too important, what’s important is turning this into a P value, a measure of how likely an outcome this strange is to come about by pure chance.
To get a P value, we use some brute-force simulation:
- Assuming the draws are uniformly distributed, generate a sample of mock data the same size as our real data
- Measure the KS statistic of this set
- Repeat steps 1 and 2 many many times
- Find whatever fraction of mock-samples have a higher KS statistic than our real data.
Something easy to get mixed up is that a small P value is more unusual. I.e. if $P=1.0$, our data is so boring that any simulation is weirder than it, and $P=0.0$ means its so unusual that $100 \%$ of the simulations fail to match is level of strangeness. You can see that the exact test statistic we use to quantify “strangeness” isn’t important, what matters is how rarely the simulations manage to meet or beat that amount of strangeness. Usually, we consider anything below $P=0.05$, i.e. a one in twenty chance, to be a good cause for concern.
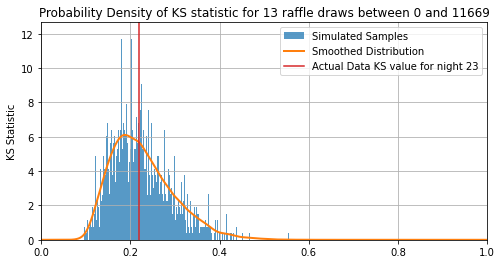
The first thing you’ll notice is that $KS=0$ is actually extremely unlikely, with the most likely outcome being some lumpiness with $KS\approx0.2$ This is because there’s one and only one way to get a perfectly uniform set of draws but any countless number of ways to get a “slightly non-uniform” result. For this particular night, the KS of the real data is $KS=0.22$, which has $51\%$ of simulations to the right of it. That means its P value is:
\[P=0.51\approx\frac{1}{2}\]I.e. one in two odds for this night, a pretty unremarkable outcome. From here, all we need to do is extend out to all $188$ nights and see if any are particularly unusual.
Part Four: Putting it Together - How Strange is Strange?
Looking at the P values for all $188$ nights, we see them running the entire range from $P=99.8\%$ to $P=0.35\%$. Some of these P values are pretty severe, one or two have roughly “1 in 300” odds of occurring, but we have to be careful not to raise a false alarm when faced with these outliers. Remember that the P value is only for each individual game: it asks “how unusual is this outcome for this game”. An outcome with 1:100 odds might seem unusual, but not so much if we play well over 100 games.
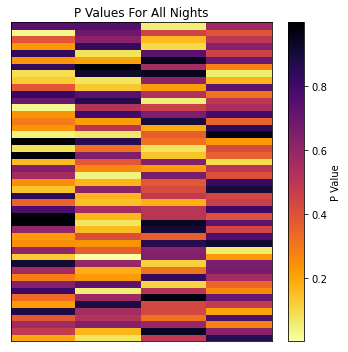
Fortunately, the maths to account for this is mercifully simple. Our P values already tell us how strange any given outcome is, and we can multiply them together to get an overall “strangeness” of the entire bank of results. For example, lets look at the strangest night, which has a P value / odds of:
\[min(P) = 0.35 \% \approx \frac{1}{286}\]But remember, this only tells us “What are the odds of getting this result in one game”, when we’ve actually got $188$ games to play with. The question we really need to be asking is:
How likely is it to play 188 games _without getting an outcome this unusual?_
This is simple grade school maths: If there’s a $0.35\%$ chance of something this strange from a given game, we have a $99.65\%$ chance of anything less strange. Now, we can ask “What is the chance of getting this unremarkable of a result 188 times in a row:”
\[P_{\text{No Strange Games}} = 0.9965 ^ {188} \approx 52 \% \approx \frac{1}{2}\]That means, thanks to the sheer number of games we played, there was a roughly 50-50 shot of playing at least one game this strange or more.
This page by Hugh McDougall, 2024
For more detailed information, feel free to check my GitHub repos or contact me directly.